Project C4 - Vision- and action-embodied language learning
PIs: Prof. Dr. Zhiyuan Liu, Dr. Cornelius Weber, Prof. Dr. Stefan Wermter
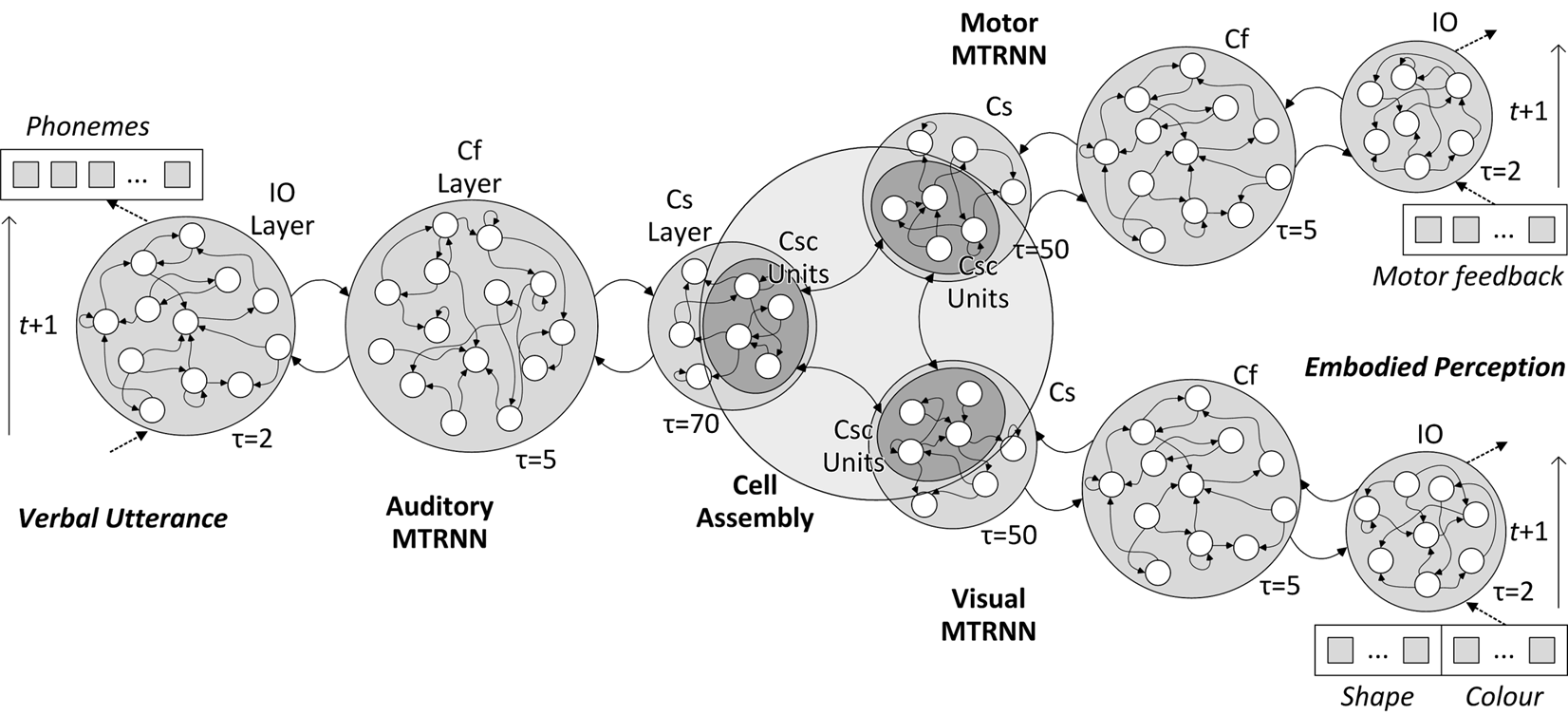
Project C4 focuses on language learning by an embodied agent—one that experiences its world through action and multisensory perception—to understand how spatio-temporal information is processed for language. The goal is to build an embodied neural- and knowledge-based model that processes audio, visual, and proprioceptive information and learns language grounded in these crossmodal perceptions. As a learning architecture, an MTRNN will be used, which is a deep recurrent neural network designed both to model temporal dependencies at multiple timescales and to reflect the recurrent connectivity of the cortex in a conceptually less complex structure.